“Is Python compiled or interpreted? Both.”
Python Internals: An Introduction
A Lovely Stroll From Launching CPython to Code Execution
Disclaimer: This article may contain more C code than Python code.
Python is fascinating and probably the closest that humanity has come so far to executable pseudo code. It attracts plenty of people who never coded before to come and try and possibly discover entirely new talents — like me. A couple of years down the line, I have moved on to core topics of Computer Science, stretching the entire curriculum of a Computer Science Degree. I have not forgotton where I came from and I look back with bliss at the time, where I bent my mind admittedly over the simplest concepts, like loops, functions and classes. Yet, the idea that I would need to run a separate program to execute my code, while since my childhood all it took to run any program on my computer was to double click a single .exe file on screen, was long time beyond me.
In this one and the next articles, I would like to explore the inner life of the CPython interpreter, foremost its runtime environment. It is not difficult to find material related to other internal features of the Python interpreter — like the compilation process or the interpretation of Bytecode. My overview is supposed to be focussing on the machine aspect of Python’s inner virtual machine. A deep dive into the source is going to be inevitable to see and understand what is actually going on. Let us first naively stroll down the callstack und miraculously gaze at how the runtime is evolving around us. We will come to the more intriguing questions eventually.
In the end, I would like to find the answers to the following questions: What does the machine in the Python virtual machine look like? How does it manage processes and threads? What is the memory layout inside the virtual machine?
From here on Python is refering to CPython version 3.9, the latest as of the time of writing. I used Windows 10 64-bit and Visual Studio 2019 to build and analyse the source. The things discussed here will likely not hold true for other implementations of Python, like Jython or IronPython. I expect the differences in using another operating system to be rather obvious whenever they occur.
I have edited and annotated any source code shown here for brevity, clarity and readability. I highly recommend reading the CPython source alongside for the having full picture.
The High-Level Overview
Is Python a compiled or interpreted language? Both. Python is compiled into bytecode, which is then interpreted by a Virtual Machine. When we feed the interpreter with Python source code, we can conceptionally imagine two steps taking place:

This is of course an overly simplified model. We will later have a brief look at the components of the Python compiler, but our focus will be the anatomy of the interpreter and its runtime.
The Project Layout
To gain a better orientation before diving into the source code, it might help to make oneself familiar with how the source directory of the CPython project is organised:

The interpreter is implemented as a shared library in the three subdirectories Objects/, Include/, and Python/. The implementation of Python’s standard library lives in a separate folder, but the C extension modules — located in the Modules/ directory— also use the Python headers, effectively loading parts of the interpreter as a library. The same is true for third-party libraries like numpy which are implemented via the Python/C API.
Traversing Down `main`
The main function shown below is located in Programs/python.c. But the actual entry point to the interpreter is Py_Main located in Modules/main.c.
Even if you have not programmed natively before, you are probably familiar with a main function. But what is wmain? Well, Windows supports both 8-bit ANSI character types as well as UTF-16, the native character type on Windows. In addition to the standard C character strings, the Windows API provides variants to all its functions accepting also the native Windows wide character strings, or UTF-16.
Three levels down the call stack, we pass by pymain_main. So far, we have fiddled a bit with command line arguments. Next a couple of initilization routines are running where a configuration object is assembled from command line arguments and environment variables. Two levels further, inside pymain_run_python, we are reaching a crossing point:
Depending on how it was invoked, the interpreter has to decide in which mode to run. Interesting note on the side: The Python interpreter has a source code representation of itself with the PyInterpreterState struct. The command line flags and arguments provided determine how to continue from here:
- The
-cflag invokes thepymain_run_commandbranch - The
-mflag takes thepymain_run_modulebranch - If instead a file name is provided,
pymain_run_fileis called - Else read anything that has potentially been piped in via
<stdin>and enter the interactive mode (pymain_run_stdinandpymain_repl)
The Bit Between Writing Code and Running Code: The Compiler
Regardless of which branch is taken, at one point the interpreter will have to take in Python source code and compile it. The Python compilation process involves four separate tansformations.
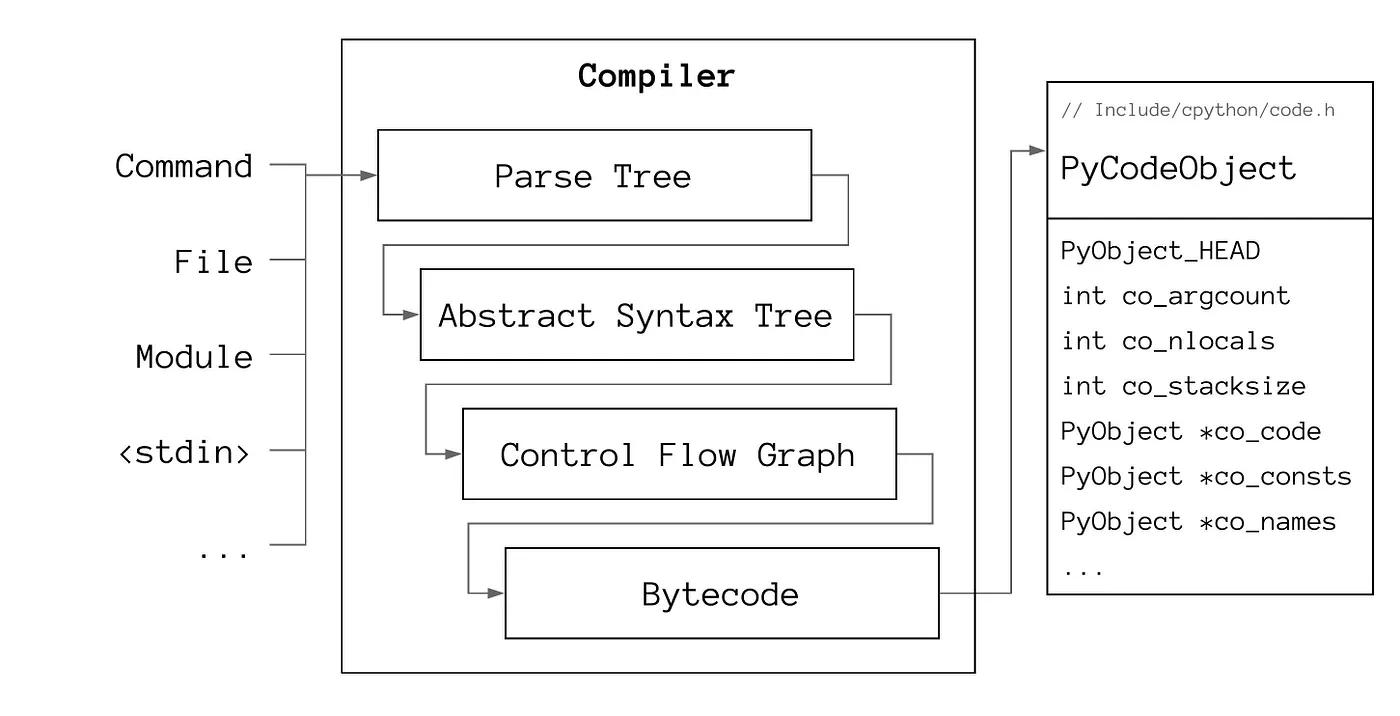
The raw source is first recieved by the parser for tokenization. The tokens are arranged as nodes in a Parse Tree, representing the lexical structure of the code. The Parse Tree is then transformed into an Abstract Syntax Tree (AST), where the tokens are grouped and interpreted as syntactic elements. The “grammar” of the Python language determines, whether a stream of lexical tokens represents syntactically correct Python code. Third, the AST is transformed into a Control Flow Graph (CFG). The CFG still has a tree structure. The compiler therefore must first flatten the graph before it can generate Bytecode. Finally, the compiler emits its output in the form of code objects, which contain the generated bytecode bundled with extra information necessary for the execution of this code unit.
Code objects are full-fledged Python objects as suggested by a) the object’s name and b) the PyObject_HEAD field in the PyCodeObject struct. That also means that they are fully inspectable at runtime — for example like so:
>>> def foo(x, y):
... return x + y
...
>>> foo.__code__
<code object foo at 0x00...0F50, file "<stdin>", line 1>>>> foo.__code__.co_code
b'|\x00|\x01\x17\x00S\x00'
We can see that the bytecode representation is very compact. In case one prefers a more human readable representation, one can use the dis module which is part of Python’s standard library:
>>> from dis import dis
>>> dis(foo.__code__)
1 0 LOAD_FAST 0 (x)
2 LOAD_FAST 1 (y)
4 BINARY_ADD
6 RETURN_VALUEThis is the disassembled version of the bytecode emitted by the compiler for our foo function. Does the Python compiler optimize code? Yes, it does — but to a very limited degree. For example, it eliminates dead code and folds simple constant expressions. If you are interested in the kind of optimizations that Python applies, have a look at PyCode_Optimize in Python/peephole.c. Before continuing our traversal, I would like to point out one oddly named field in PyCodeObject, called void *co_zombieframe. It is an artifact of Python’s memory management strategy and it will reappear later in a more sensible context when talking about memory management.
This is as much as we are going to discuss the compiler. Interested readers can find more detailed information in the Python Developer Guide (s. [5]) and although it is a bit dated by now, I can also highly recommend Eli Bendersky’s Blog (s. [2]).
The Final Mile: Code Objects and Code Evaluation
Back to where we were: Retrieving our source code is a bit more involved when running in interactive mode or when running a module in Python, because Python has more work to do gathering all the necessary files or prompting input from the user. In fact, when you are running a module, the interpreter actually dispatches most of the responsibility to the runpy module — also part of Python’s standard library. But regardless of the interpreter mode, paths converge again when the code object is handed to run_eval_code_obj. From there it is passed down some unspectacular functions until it hits _PyEval_EvalCode. Meanwhile, we have arrived in Python/ceval.c.
Here are three objects that are tightly connected to teach other: The already familiar PyCodeObject, PyFrameObject, and PyThreadState. The original function including the parts that I have omitted is a bit of a mouthful. Most of it serves in the initialization of the frame object. A frame object can be understood as a runtime representation of a code object, not unlike a process is a runtime representation of a program.
If you already had some familiarity with Python’s internal architecture, you may already know what comes next: The core interpreter loop with an infamously large switch-statement.
Huh, odd... This is not the 2000+ lines core evaluation loop that we expected to see. The evaluation function for this frame is dynamically invoked through a function pointer that had been stored inside the PyInterpreterState instance at some point earlier during initialization. The function pointer is opaque to where precisely it dispatches, but its naming gives a clue. To understand what happens beyond this point, let us step back again and look at the initialization process.
The Runtime
Going back to where we came from, remember that we passed the first initialization routine in pymain_main — the third level in the call stack. We briefly mentioned that initialization took place, but stepped over the call to pymain_init.
Runtime State
The initialization of Python takes place in three distinct steps. The first is the initialization of the Python runtime. The _PyRuntime is statically initialized in Python/pylifecycle.c. It is a _PyRuntimeState struct, which itself is defined in Include/internal/pycore_runtime.h. It monitors a number of behind-the-scenes-states not directly exposed to userspace.

Figure 4 shows the three fields of the runtime state, which are going to be of most interest going forward. The first field appears to be a linked list of interpreter states. The next two fields point two subsystems whose naming is a bit less obvious: _ceval_runtime_state and _gilstate_runtime_state.
The ceval state is the first subsystem that gets initialized by _PyRuntimeState_Init_impl in Python/pystate.c. The ceval state is a proxy for Python/ceval.c. Its responsiblity is to manage and ensure save access to the frame evaluator — _PyEval_EvalFrameDefault, which we have not looked at yet. Oddly enough, the evaluator is not bound to the ceval state, but — as we have seen before — it is referenced and called through the running interpreter state instance. Ceval state still fulfills a crucial role in the evaluation of frame objects: It keeps track of who is currently in possession of the Global Interpreter Lock (GIL) and who is therefore allowed to enter the evaluation loop. What precisely is the GIL? This is a heavily debated relic of the of the time when mulit-threading still meant multiple threads executing on one core, not many. The role of the GIL and what it does will become clearer in the next article, when we are talking about parallelism and data coherence.
After setting the locale and some environment variables, the default allocator for the interpreter is configured. There are four different allocators available and each comes in three domain specific flavours: PYMEM_DOMAIN_RAW, PYMEM_DOMAIN_MEM and PYMEM_DOMAIN_OBJ. The last one is obviously the domain for allocating Python objects, while the prior two are passing allocation requests through to the system allocator and differ only in whether they control for thread safety or not. The available allocators are default, debug, pymalloc — incidently the default allocator — and malloc.
Interpreter, Garbage Collector and the Main Thread
The last bit of the initialization takes place in two steps: First the core initialization and then the main initialization. pyinit_core in Python/pylifecycle.c creates the first interpreter instance and with it the first thread. In PyInterpreterState_New we find what we were looking for:
The interpreter receives its frame evaluator: A function pointer to _PyEval_EvalFrameDefault. The new interpreter is then added to the list of runtime interpreters that we have seen in figure 4. We can spot one more important submodule of the interpreter being intiailized: the Garbage Collector.
The initalization of the garbarge collector is done by _PyGC_InitState in Modules/gcmodule.c. Without knowing yet the precise inner workings, we see the garbage collector receiving an array of three GC generations. Each generation in turn has a head pointer to a linked list of objects that are tracked by the garbage collector. The garbage collector itself maintains a head pointer to the generation zero list of objects.

The count is the number of live objects currently tracked in each generation and threshold is the number of tracked objects per generation that will trigger a collection attempt by the garbage collector. The thresholds are initialized to 700, 10, 10 for the first, second and third generation respectively. You may think that the thresholds appear low enough that they should be frequently hit even by average applications. After all, every integer, every float is a PyObject with all the associated baggage. But the Python garbage collector in fact does not track every type of Python object, but only those at risk of creating reference cycles — primarily mutable containers. Reference cycles prevent the reference count of an object to ever reach zero and therefore, from being deallocated — in other words: they leak memory. The garbage collector’s role in Python is to prevent this from happening.
Next a new PyThreadState is created. It receives a accessor method to retrieve its own current frame and then takes the Global Interpreter Lock.
After the runtime core has been initialized, the first interpreter and its first thread is up and running. The main initialization, which finalizes the initialization process, lastly sets up all the builtin modules, like sys and __main__, and other features exposed to the Python programmer.
With the frame evaluator we have all the building blocks together to enter the evaluation loop: An interpreter and a thread providing the necessary context for the evaluation, a frame object to evaluate and the associated code object with the list of opcodes. Before we proceed, I highly recommend taking a look at the main evaluation loop — it is well document, it is massive, it is beautiful, it is most of all outstandingly intuitive to read, which is an achievement in itself.
Conclusion
The attentive reader will have noticed, that I have not in fact answered the initially posed questions to a satisfying degree. But for the sake of my own sanity and the attention span of everyone else, we are going to spend time on each question in a dedicated article respectively, looking at the Python runtime from various angles.
In this article we have approached the CPython source code from a naive, but hopefully intuitive perspective: We started from the entry point of the interpreter, gradually proceeding further downward the callstack and closely observing how the execution environment evolves. In the process we have located a whole series of crucial subsystems almost in a drive-by fashion.
The next article will be concerned with Python processes and threads. We are going to explore in more detail the roles that the interpreter state, the thread state and frame objects play in the evaluation of Python code. We are going to look at how Python organises and retrieves data at runtime, how it maintains data coherence and order of execution in a multi-threaded, multi-process environment, and in the process lift the mystery around the Global Interpreter Lock.
Lastly, we are going to have a look at Python’s memory management strategy. This involves Python’s strategy for allocating and deallocating objects. But it also touches the life time management of objects and how to use the available memory space most efficiently to reduce performance overhead.
It is going to be tough work, but I am already looking forward to it.
References
[1] A. Shaw: Your Guide to the CPython Source Code. Real Python, 2019, https://realpython.com/cpython-source-code-guide/. Last visited Aug. 02, 2020.
[2] E. Bendersky: Python internals. 2009–2015, https://eli.thegreenplace.net/tag/python-internals. Last visited Aug. 02, 2020.
[3] G. v. Rossum: The History of Python. Python’s Design Philosophy. 2009, http://python-history.blogspot.com/2009/01/pythons-design-philosophy.html. Last visited Aug. 02, 2020.
[4] P. Guo: CPython internals: A ten-hour codewalk through the Python interpreter source code. 2014, http://pgbovine.net/cpython-internals.htm. Last visited Aug. 02, 2020.
[5] Python Developer’s Guide: Design of CPython’s Compiler. Python Software Foundation, 2020, https://devguide.python.org/compiler/. Last visited Aug. 02, 2020.
[6] Python Developer’s Guide: Exploring CPython’s Internals. Python Software Foundation, 2020, https://devguide.python.org/compiler/. Last visited Aug. 02, 2019.
[7] Y. Aknin: Python’s Innards. 2020, https://tech.blog.aknin.name/category/my-projects/pythons-innards/. Last visited Aug. 02, 2020.